Demystifying bootstrap_stat_plot(): Your Ticket to Insightful Data Exploration
code
rtip
tidydensity
Author
Steven P. Sanderson II, MPH
Published
January 22, 2024
Introduction
Ever feel like your data is hiding secrets? Like it’s whispering truths but you just can’t quite grasp them? Well, fear not, fellow data sleuths! Today, we’ll crack the code of an R function that’s like a magnifying glass for your statistical investigations: bootstrap_stat_plot() from the TidyDensity package.
Imagine this: You have a dataset, say, car mileage (MPG) from the classic mtcars dataset. You want to understand the average MPG, but what if that average is just a mirage? What if it’s skewed by a few outliers or doesn’t capture the full story?
Enter bootstrapping, a statistical technique that’s like taking your data on a wild ride. It creates multiple copies of your data, each with a slight twist, and then calculates the statistic you’re interested in (e.g., average MPG) for each copy. This gives you a distribution of possible averages, revealing the variability and potential biases lurking beneath the surface.
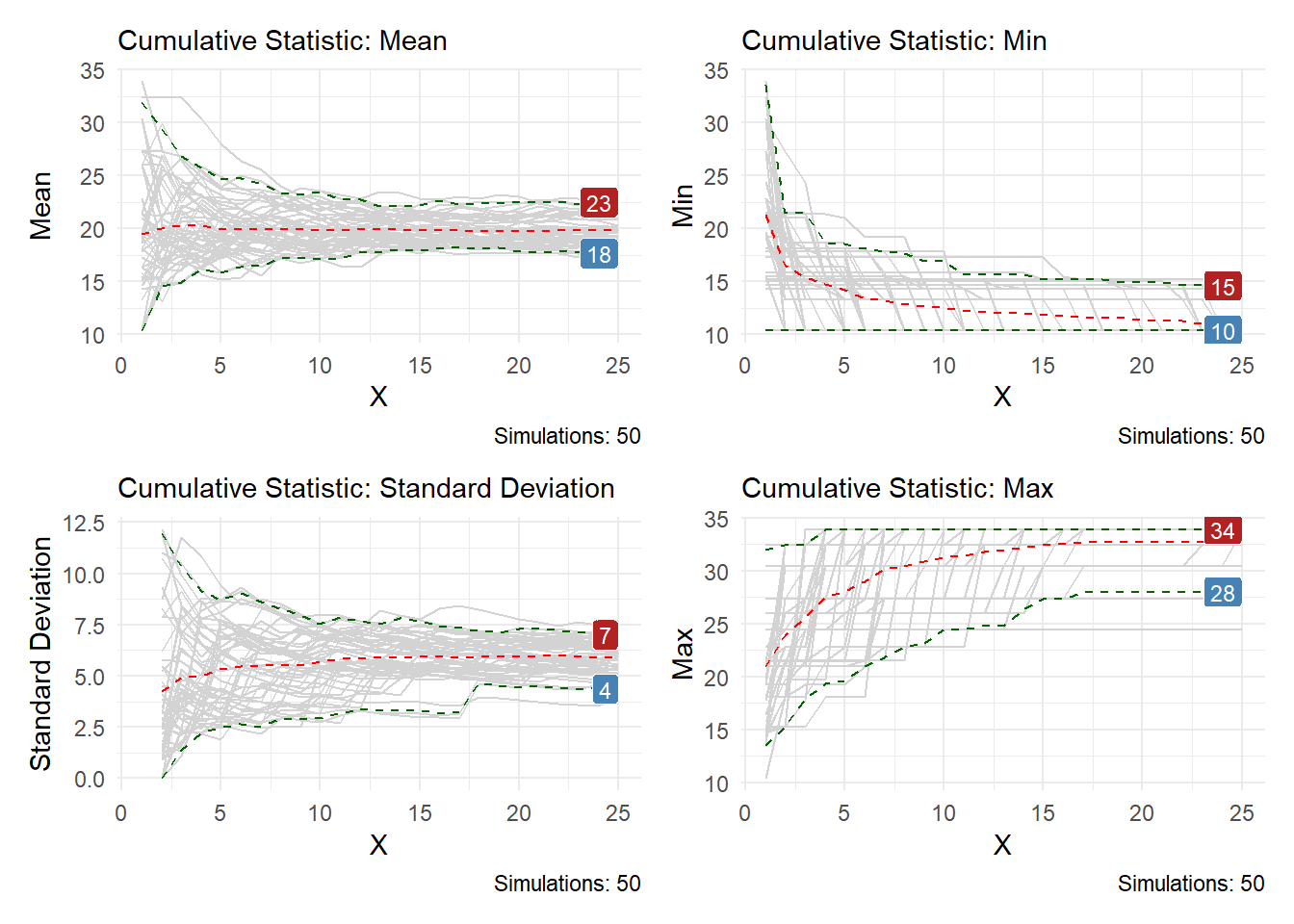
bootstrap_stat_plot() takes this magic a step further. It not only calculates the distribution but also visualizes it, giving you a clear picture of how the statistic fluctuates across different versions of your data. It’s like a magnifying glass for your statistical investigations!
.data: This is where your bootstrapped data lives, usually after using tidy_bootstrap() or bootstrap_unnest_tbl() to create it.
2. The Statistic:
.value: This is the column you want to analyze, like mpg in our example.
.stat: This is the magic spell! It tells the function what statistic to calculate on your chosen value. By default, it’s "cmean" for the cumulative mean, but you can choose others like "cmin" for the minimum, "cmax" for the maximum, or even "csd" for the circular standard deviation.
3. Visualization Options:
.show_groups: Turn this to TRUE if you want to see the distribution for each bootstrap sample (think of it as a swarm of data points). By default, it shows just the overall distribution.
.show_ci_labels: This one displays the confidence interval bounds (think of it as the range where the true statistic likely lies). By default, you get the last values of the upper and lower bounds.
4. Interactive Mode:
.interactive: Set this to TRUE if you want to get a plotly plot object back, which you can then customize further. Think of it as a living graph you can play with!
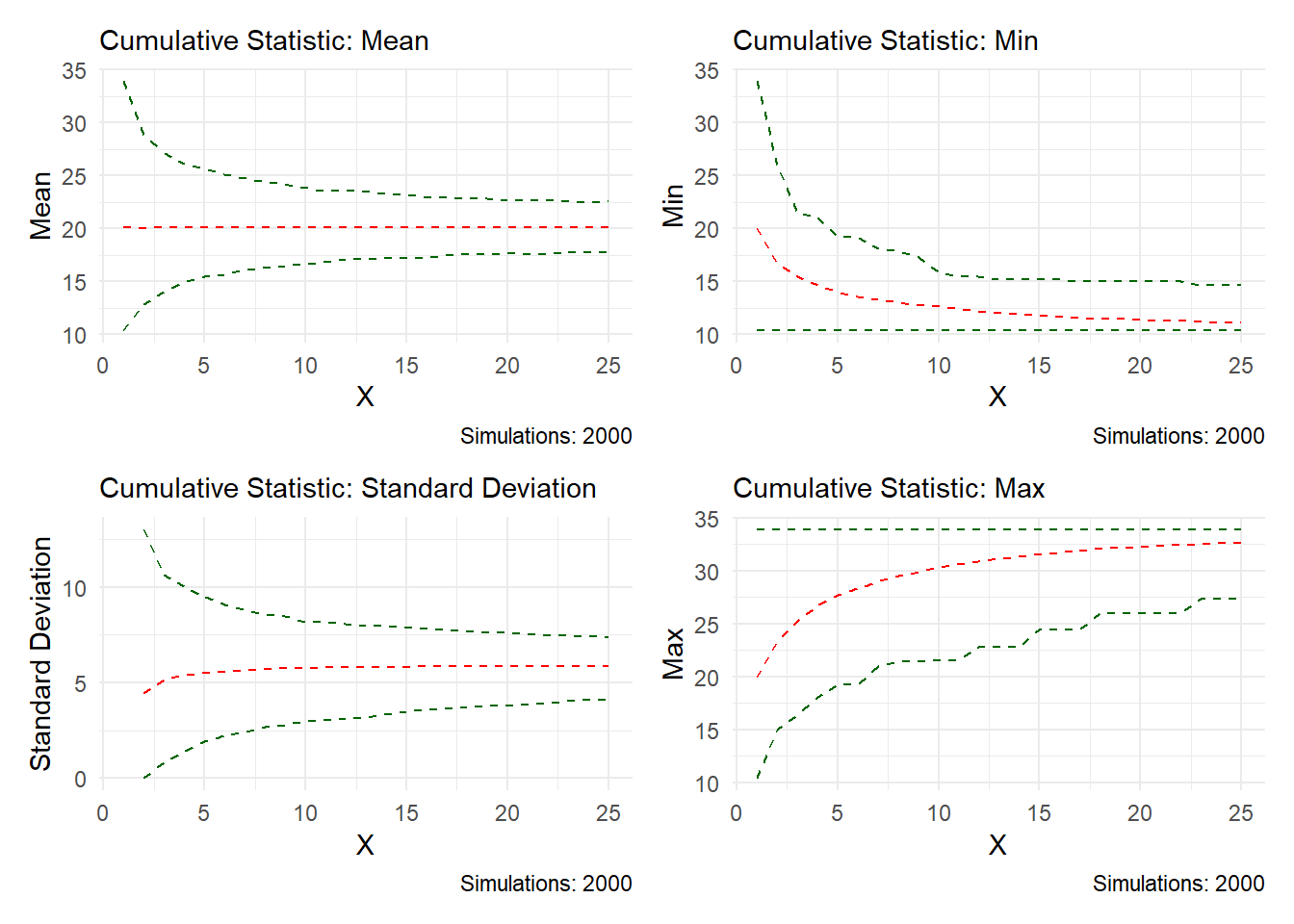
In this example we did two things different, we hid the replications, the simulations was left to the default of 2000 and the labels were turned off. This is useful when you want to show a summary of the data.
Your Turn to Explore
Don’t just take our word for it! Try bootstrap_stat_plot() on your own data. Experiment with different statistics, explore the interactive mode, and see how it unlocks new insights you might have missed before. Remember, the more you play, the more you discover!
So, unleash your inner data detective and let bootstrap_stat_plot() guide you to a deeper understanding of your data. Happy exploring!