This is going to serve as a sort of primer for the {TidyDensity} package.
The goal of {TidyDensity} is to make working with random numbers from different distributions easy. All tidy_ distribution functions provide the following components:
[r_]
[d_]
[q_]
[p_]
Installation
You can install the released version of {TidyDensity} from CRAN with:
This is a basic example which shows you how to solve a common problem, which is, how do we generate randomly generated data from a normal distribution of some mean, and some standard deviation with n points and sims number of simulations?
With the function tidy_normal() we can generate such data. All functions that are condsidered tidy_ distribution functions, meaning those that generate randomly generated data from some distribution, have the same API call structure.
For example, using tidy_normal() the full function call at it’s default is as follows:
What this means is that we want to generate 50 points from a standard normal distribution of mean 0 and with a standard deviation of 1, and we want to generate a single simulation of this data.
What comes back we see is a tibble. This is true for all functions in the {TidyDensity} library. It was a goal to return items that are consistent with the tidyverse.
Now let’s talk a bit about what was actually returned. There are a few columns that are returned, these are referred to as the r, d, p, and q
[r_] Shows as y and is the randomly generated data from the underlying distribution.
[d_] Two components come back, dx and dy where these are generated from the [stats::density()] function with n set to .n from the function input.
[p_] Shows as p and is the results of the p_ function, in this case pnorm() where the x of the input goes from 0-1 with .n points.
[q_] Shows as q and is the results of the q_ function, in this case qnorm() where the x of the input goes from 0-1 with .n points.
Now you will also see two more columns, namely, sim_number a factor column and x an integer column. The sim_number column represents the current simulation for which data was drawn, and the x represents the nth point in that simulation.
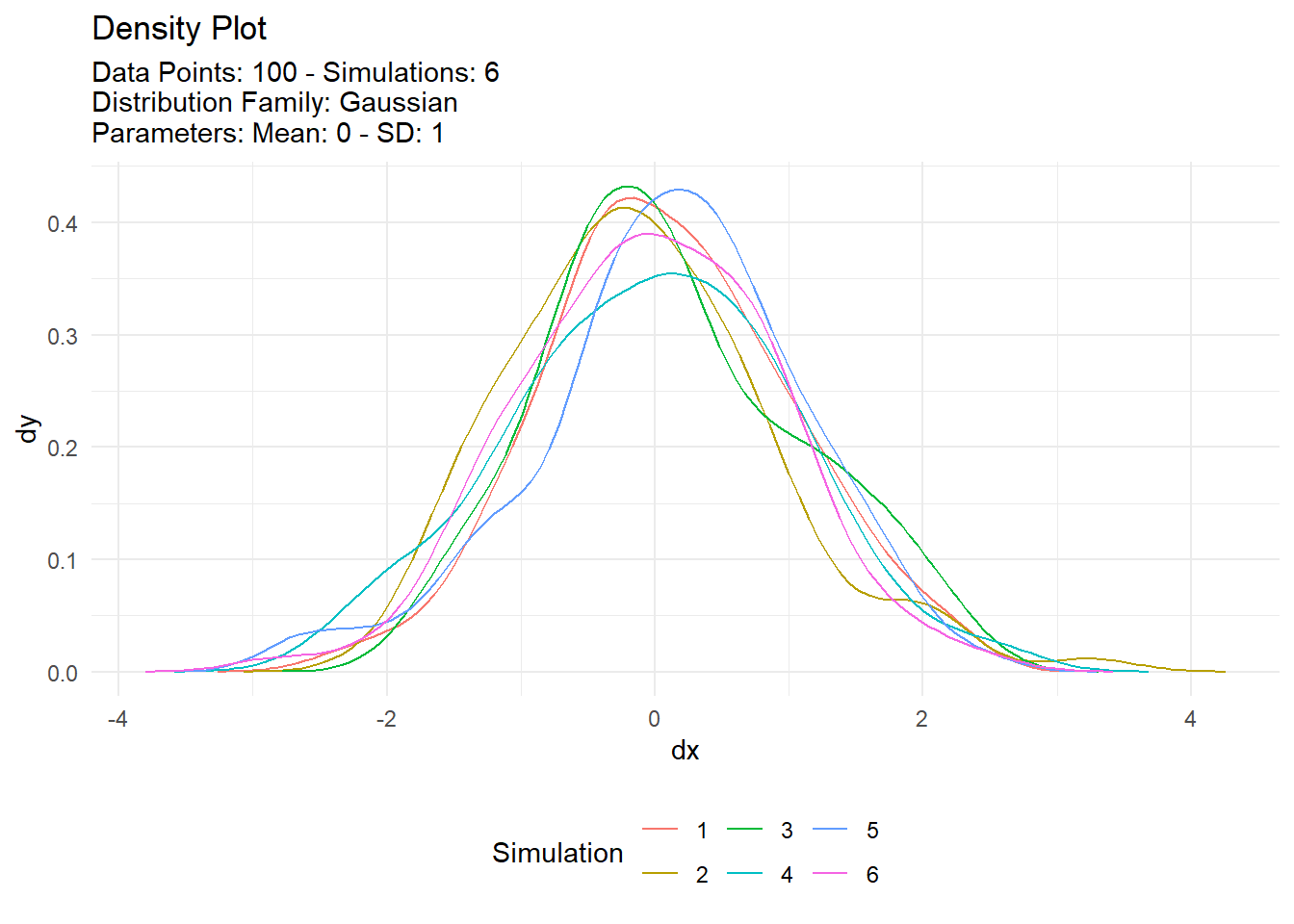
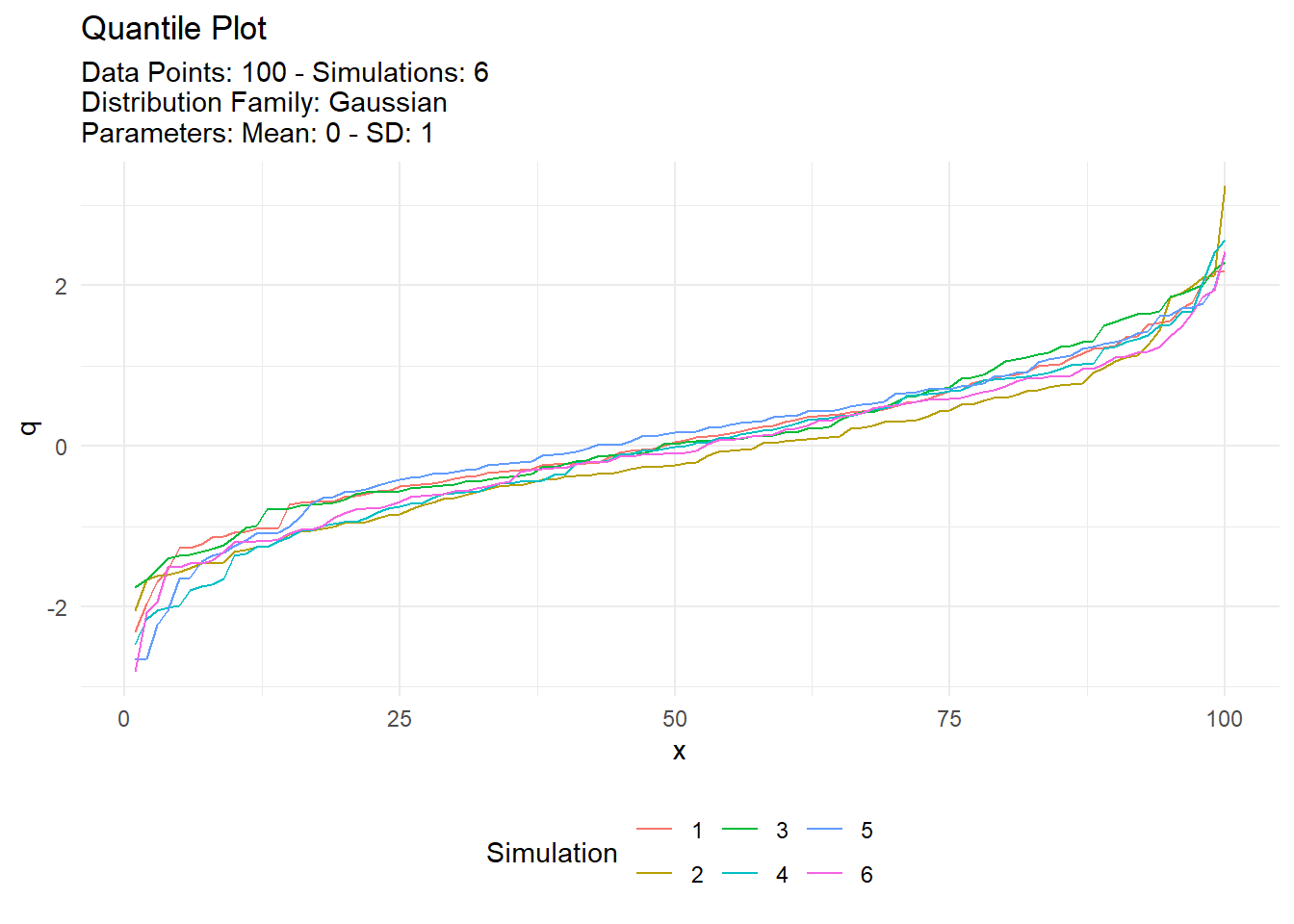
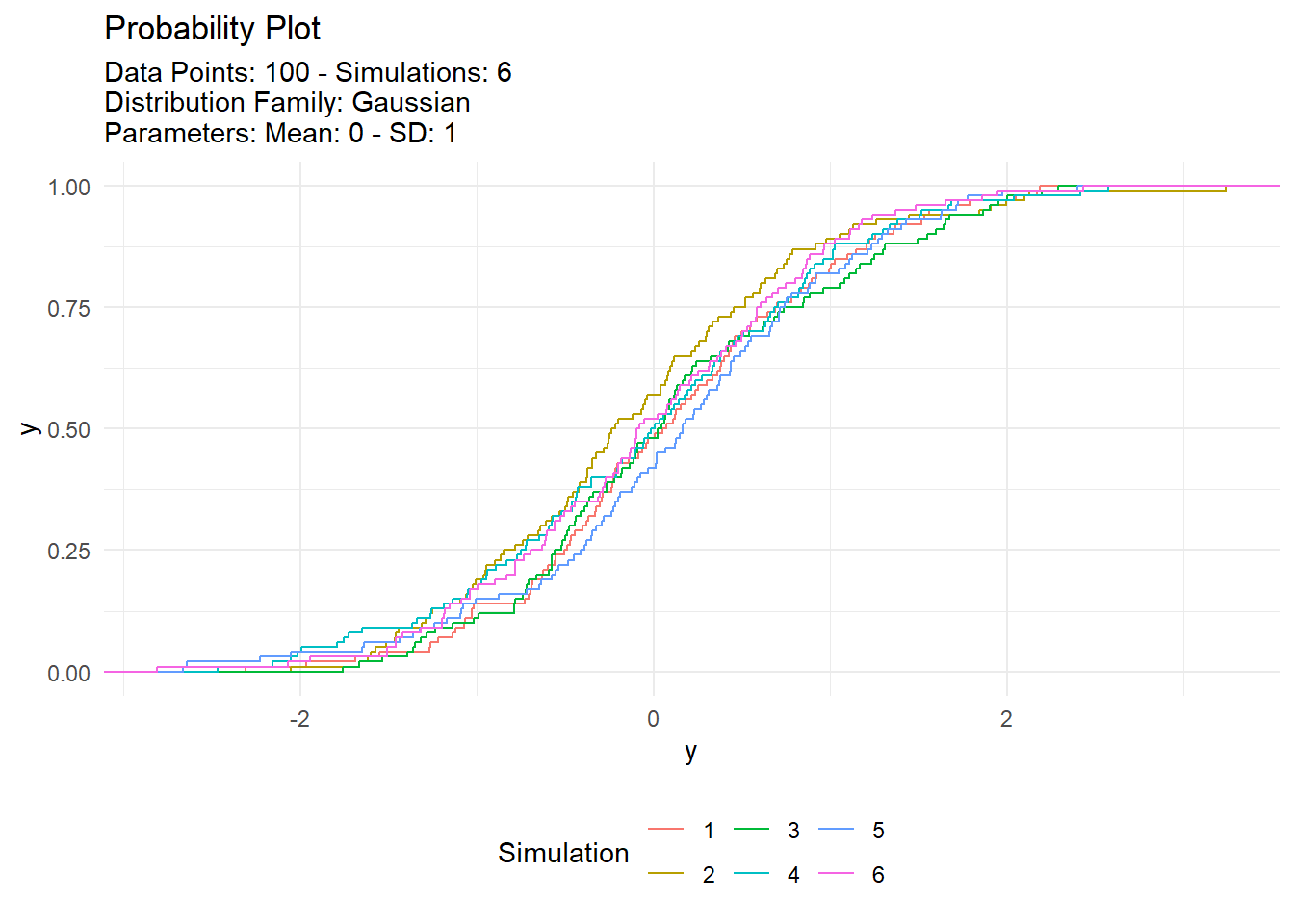
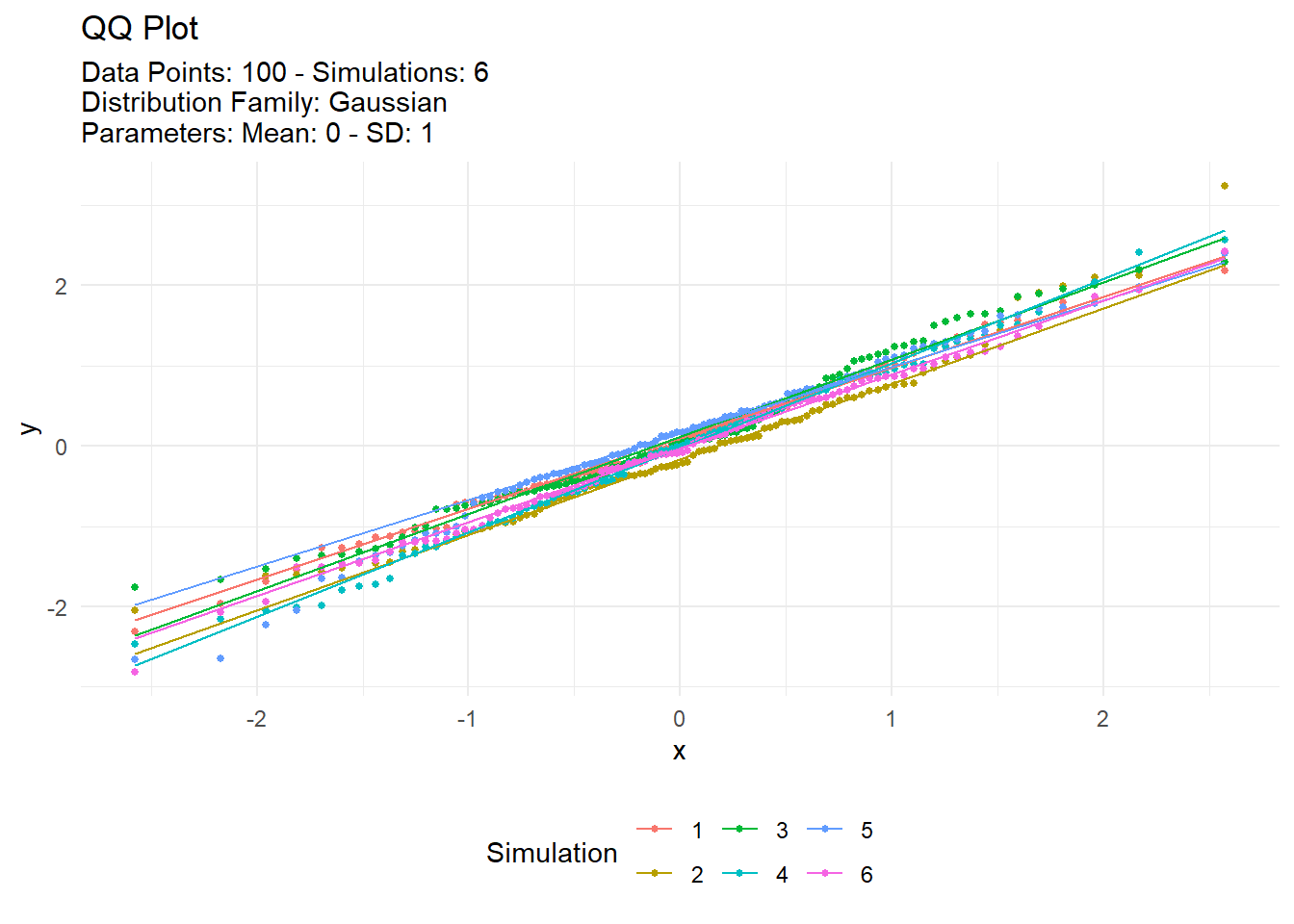
Visualization Example
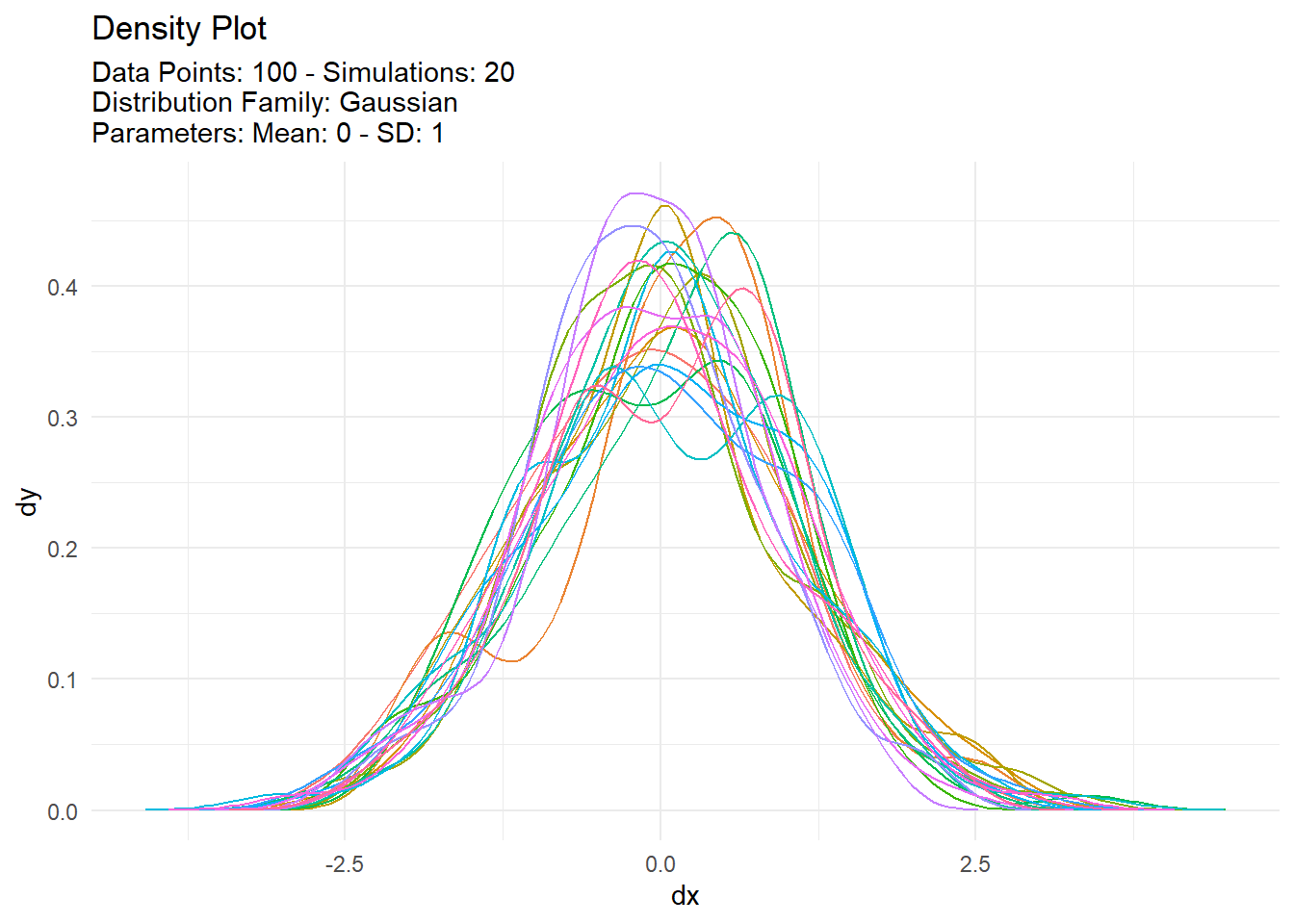
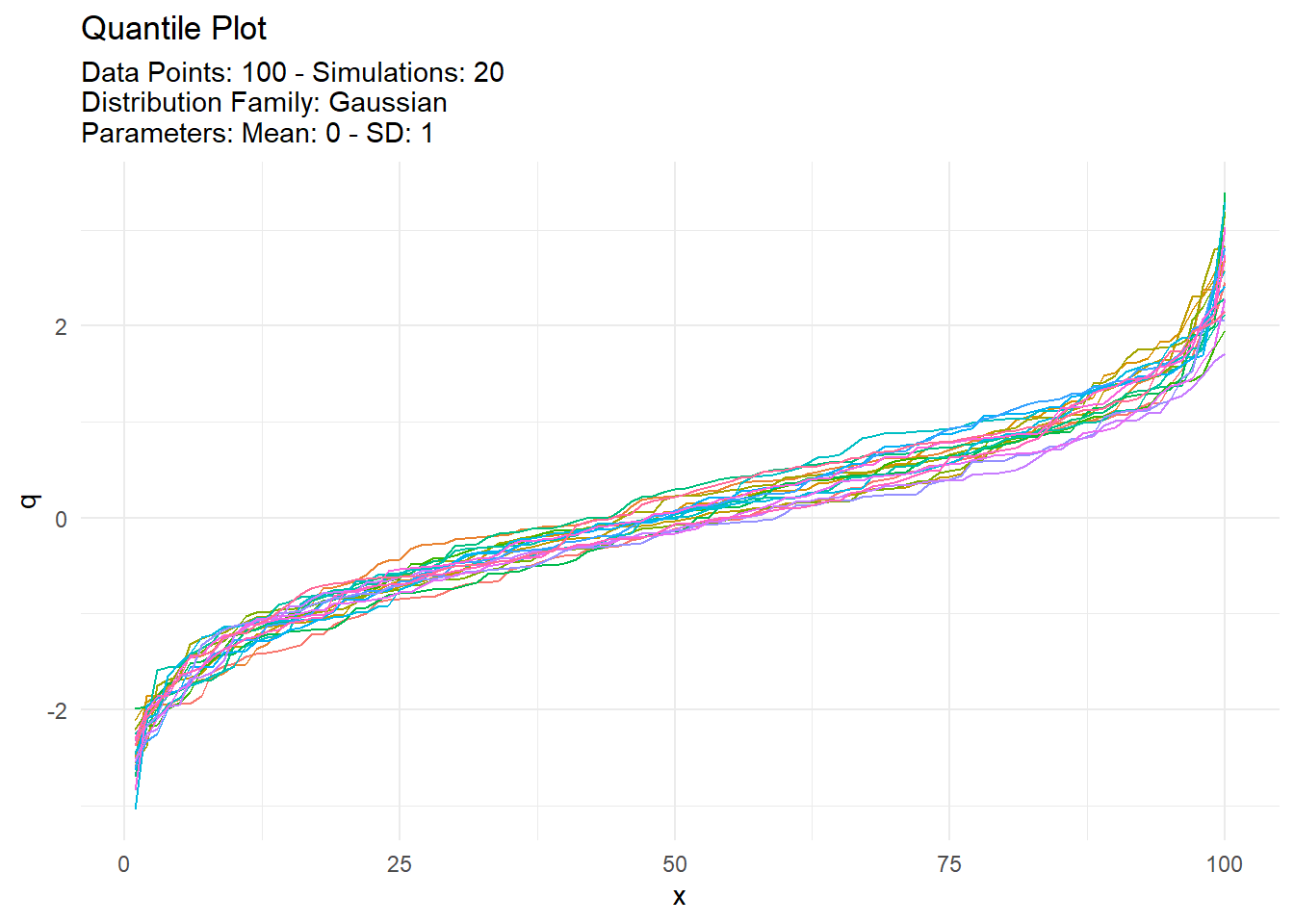
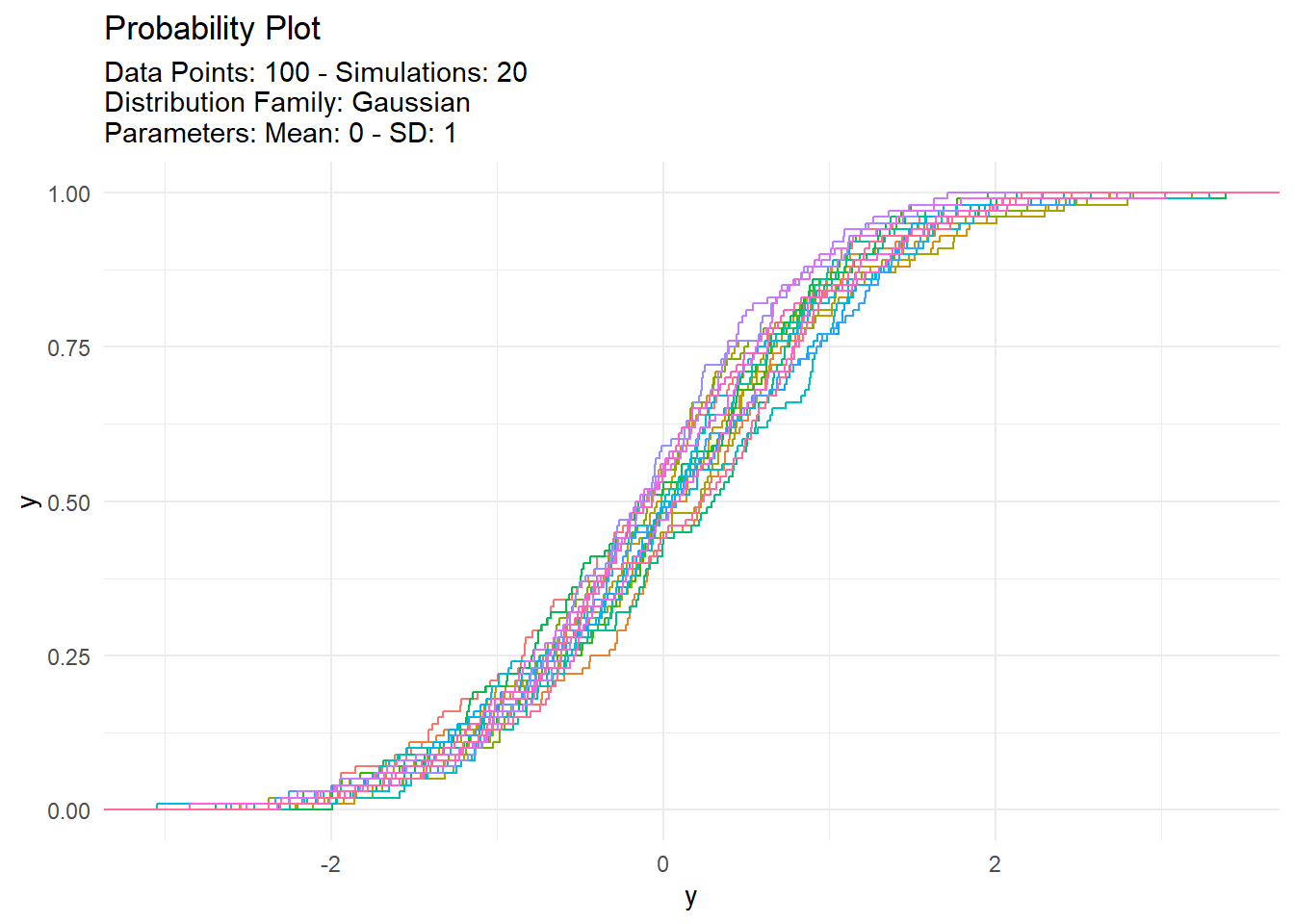
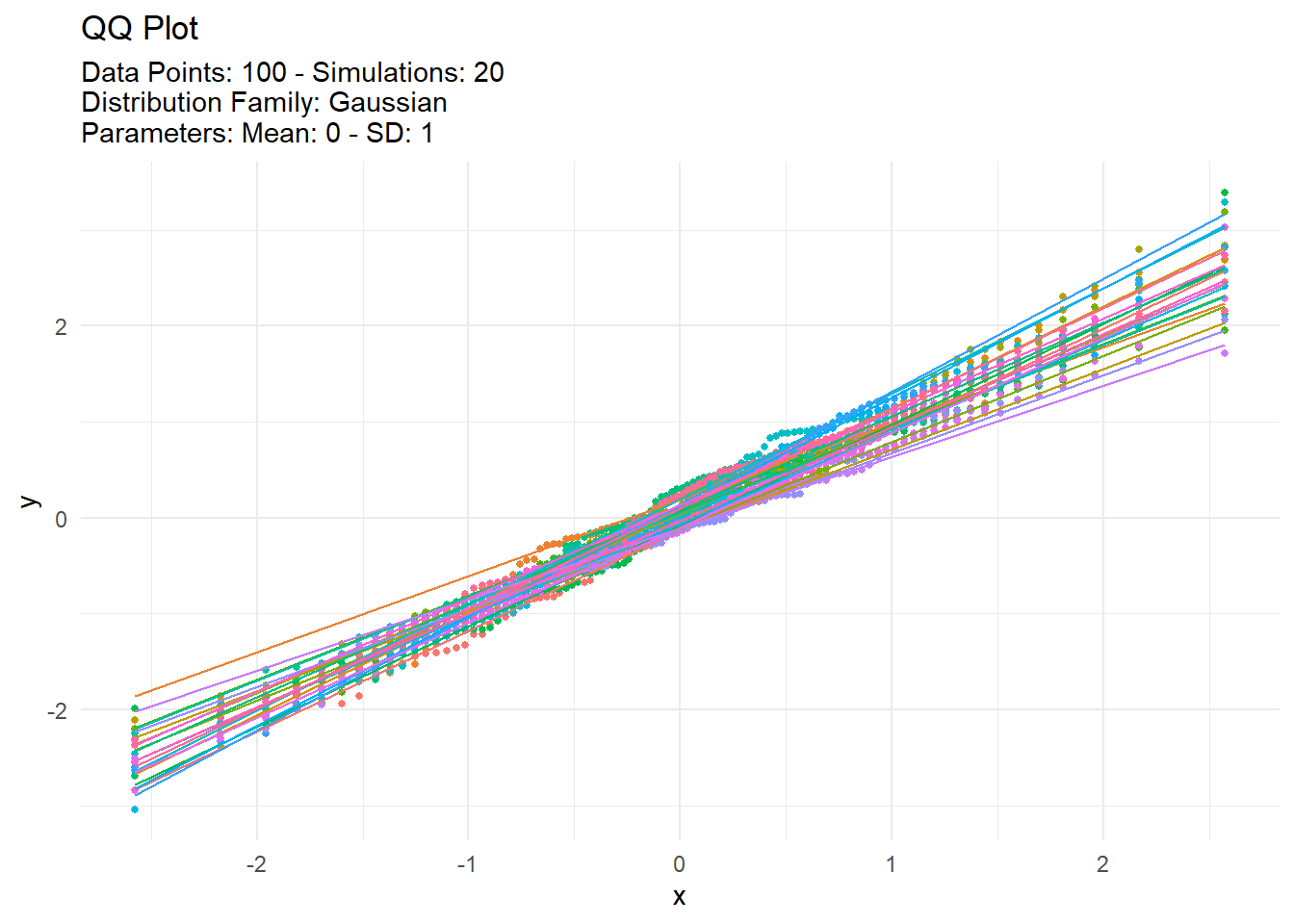
With data typically comes the need to see it! Show me the data! TidyDensity has a variety of autoplot functionality that will present only data from a tidy_ distribution function. We will take a look at output from tidy_normal() and set a see otherwise everytime this site is rendered the data would change.
We can see that the plots are faily informative. There are the regular density plot, the quantile plot, probability and qq plots. The title and subtitle of these plots are generated from attributes that are attached to the output of the tidy_ distribution function. Let’s take a look at the attributes of tn