install.packages("healthyverse")
library(healthyverse)A Review of 2023
2023 A Year in Review
The year 2023 was a big year for me. I did a lot of coding, a lot more than I typically do. The biggest push came personally in my ongoing development of my R packages that are in the healthyverse. To use the healthyverse simply do so in the familiar fashion:
Here are links to all of the packages:
In order to start looking at some of the data that pertains to 2023 lets first get the data from the CRAN logs. Since I do this daily already, I can simply use the rds file I already have. I am going to go through the motions though, in case others might want to do something similar. The functions I am using to get the data can be found here
Now lets get that data!
library(tidyverse)
library(lubridate)
source("01_scripts/get_data_functions.R")
source("01_scripts/data_manipulation_functions.R")
source("01_scripts/mapping_functions.R")
get_cran_data()
get_package_release_data()
csv_to_rds()Ok now that we have our data, lets ensure that we are only using the year 2023. We can do this by filtering out data by time with the timetk package.
Now lets filter our data below, some pre-processing may need to take place.
library(timetk)
data_tbl <- downloads_processed_tbl() %>%
filter_by_time(
.date_var = date,
.start_date = "2023",
.end_date = "2023"
)
glimpse(data_tbl)Rows: 32,438
Columns: 11
$ date <date> 2023-01-01, 2023-01-01, 2023-01-01, 2023-01-01, 2023-01-01,…
$ time <Period> 2H 32M 10S, 9H 45M 29S, 9H 45M 40S, 9H 45M 51S, 9H 45M 51…
$ date_time <dttm> 2023-01-01 02:32:10, 2023-01-01 09:45:29, 2023-01-01 09:45:…
$ size <int> 2016932, 604699, 2652829, 2297618, 2331476, 84561, 251193, 2…
$ r_version <chr> NA, NA, NA, NA, NA, NA, NA, "4.1.1", "4.1.1", "4.1.1", "4.1.…
$ r_arch <chr> NA, NA, NA, NA, NA, NA, NA, "x86_64", "x86_64", "x86_64", "x…
$ r_os <chr> NA, NA, NA, NA, NA, NA, NA, "mingw32", "mingw32", "mingw32",…
$ package <chr> "healthyR.ts", "healthyR.ai", "healthyR.data", "healthyR.ts"…
$ version <chr> "0.2.5", "0.0.10", "1.0.1", "0.2.5", "0.2.0", "1.0.2", "0.0.…
$ country <chr> "AU", "US", "US", "US", "US", "US", "AU", "BE", "BE", "BE", …
$ ip_id <int> 5938, 11, 11, 11, 11, 11, 5938, 14255, 14255, 14255, 14255, …Now that we have our data, we have it for the year 2023 only with a start date of 2023-01-01 and an end date of 2023-12-31.
Package Information
The first thing we will do is look at how many downloads there were for each pacakge and it’s version.
library(knitr)
data_tbl %>%
count(package, version) %>%
pivot_wider(
id_cols = version
, names_from = package
, values_from = n
, values_fill = 0
) %>%
arrange(version) %>%
kable()| version | TidyDensity | healthyR | healthyR.ai | healthyR.data | healthyR.ts | healthyverse | tidyAML |
|---|---|---|---|---|---|---|---|
| 0.0.1 | 156 | 0 | 106 | 0 | 0 | 0 | 788 |
| 0.0.10 | 0 | 0 | 210 | 0 | 0 | 0 | 0 |
| 0.0.11 | 0 | 0 | 431 | 0 | 0 | 0 | 0 |
| 0.0.12 | 0 | 0 | 683 | 0 | 0 | 0 | 0 |
| 0.0.13 | 0 | 0 | 1989 | 0 | 0 | 0 | 0 |
| 0.0.2 | 0 | 0 | 107 | 0 | 0 | 0 | 1804 |
| 0.0.3 | 0 | 0 | 106 | 0 | 0 | 0 | 468 |
| 0.0.4 | 0 | 0 | 107 | 0 | 0 | 0 | 0 |
| 0.0.5 | 0 | 0 | 158 | 0 | 0 | 0 | 0 |
| 0.0.6 | 0 | 0 | 436 | 0 | 0 | 0 | 0 |
| 0.0.7 | 0 | 0 | 107 | 0 | 0 | 0 | 0 |
| 0.0.8 | 0 | 0 | 104 | 0 | 0 | 0 | 0 |
| 0.0.9 | 0 | 0 | 110 | 0 | 0 | 0 | 0 |
| 0.1.0 | 0 | 107 | 0 | 0 | 112 | 0 | 0 |
| 0.1.1 | 0 | 107 | 0 | 0 | 122 | 0 | 0 |
| 0.1.2 | 0 | 123 | 0 | 0 | 105 | 0 | 0 |
| 0.1.3 | 0 | 109 | 0 | 0 | 104 | 0 | 0 |
| 0.1.4 | 0 | 109 | 0 | 0 | 109 | 0 | 0 |
| 0.1.5 | 0 | 108 | 0 | 0 | 111 | 0 | 0 |
| 0.1.6 | 0 | 109 | 0 | 0 | 111 | 0 | 0 |
| 0.1.7 | 0 | 157 | 0 | 0 | 158 | 0 | 0 |
| 0.1.8 | 0 | 438 | 0 | 0 | 437 | 0 | 0 |
| 0.1.9 | 0 | 108 | 0 | 0 | 107 | 0 | 0 |
| 0.2.0 | 0 | 880 | 0 | 0 | 107 | 0 | 0 |
| 0.2.1 | 0 | 2363 | 0 | 0 | 110 | 0 | 0 |
| 0.2.10 | 0 | 0 | 0 | 0 | 503 | 0 | 0 |
| 0.2.11 | 0 | 0 | 0 | 0 | 527 | 0 | 0 |
| 0.2.2 | 0 | 0 | 0 | 0 | 108 | 0 | 0 |
| 0.2.3 | 0 | 0 | 0 | 0 | 114 | 0 | 0 |
| 0.2.4 | 0 | 0 | 0 | 0 | 113 | 0 | 0 |
| 0.2.5 | 0 | 0 | 0 | 0 | 162 | 0 | 0 |
| 0.2.6 | 0 | 0 | 0 | 0 | 424 | 0 | 0 |
| 0.2.7 | 0 | 0 | 0 | 0 | 816 | 0 | 0 |
| 0.2.8 | 0 | 0 | 0 | 0 | 1255 | 0 | 0 |
| 0.2.9 | 0 | 0 | 0 | 0 | 700 | 0 | 0 |
| 0.3.0 | 0 | 0 | 0 | 0 | 507 | 0 | 0 |
| 1.0.0 | 105 | 0 | 0 | 107 | 0 | 123 | 0 |
| 1.0.1 | 427 | 0 | 0 | 940 | 0 | 105 | 0 |
| 1.0.2 | 0 | 0 | 0 | 1377 | 0 | 537 | 0 |
| 1.0.3 | 0 | 0 | 0 | 1831 | 0 | 451 | 0 |
| 1.0.4 | 0 | 0 | 0 | 0 | 0 | 1576 | 0 |
| 1.1.0 | 104 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1.2.0 | 106 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1.2.1 | 104 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1.2.2 | 106 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1.2.3 | 105 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1.2.4 | 1979 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1.2.5 | 1889 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1.2.6 | 956 | 0 | 0 | 0 | 0 | 0 | 0 |
Now lets see how many total downloads for the year there were for each package.
data_tbl %>%
count(package) %>%
set_names("Package","Total Downloads") %>%
kable()| Package | Total Downloads |
|---|---|
| TidyDensity | 6037 |
| healthyR | 4718 |
| healthyR.ai | 4654 |
| healthyR.data | 4255 |
| healthyR.ts | 6922 |
| healthyverse | 2792 |
| tidyAML | 3060 |
data_tbl %>%
select(package, version) %>%
group_by(package) %>%
distinct() %>%
mutate(release_count = n()) %>%
ungroup() %>%
select(package, release_count) %>%
distinct() %>%
set_names("Package", "Number of Releases") %>%
kable()| Package | Number of Releases |
|---|---|
| healthyR.ts | 23 |
| healthyR.ai | 13 |
| healthyR.data | 4 |
| healthyR | 12 |
| healthyverse | 5 |
| TidyDensity | 11 |
| tidyAML | 3 |
total_number_of_releases <- data_tbl %>%
select(package, version) %>%
group_by(package) %>%
distinct() %>%
mutate(release_count = n()) %>%
ungroup() %>%
select(package, release_count) %>%
distinct() %>%
summarise(total = sum(release_count, na.rm = TRUE))So all in all there was a total of 32,438 downloads of all the healthyverse packages in 2023. There were in total 71 package releases as well.
Graphs
Now lets graph the data out!
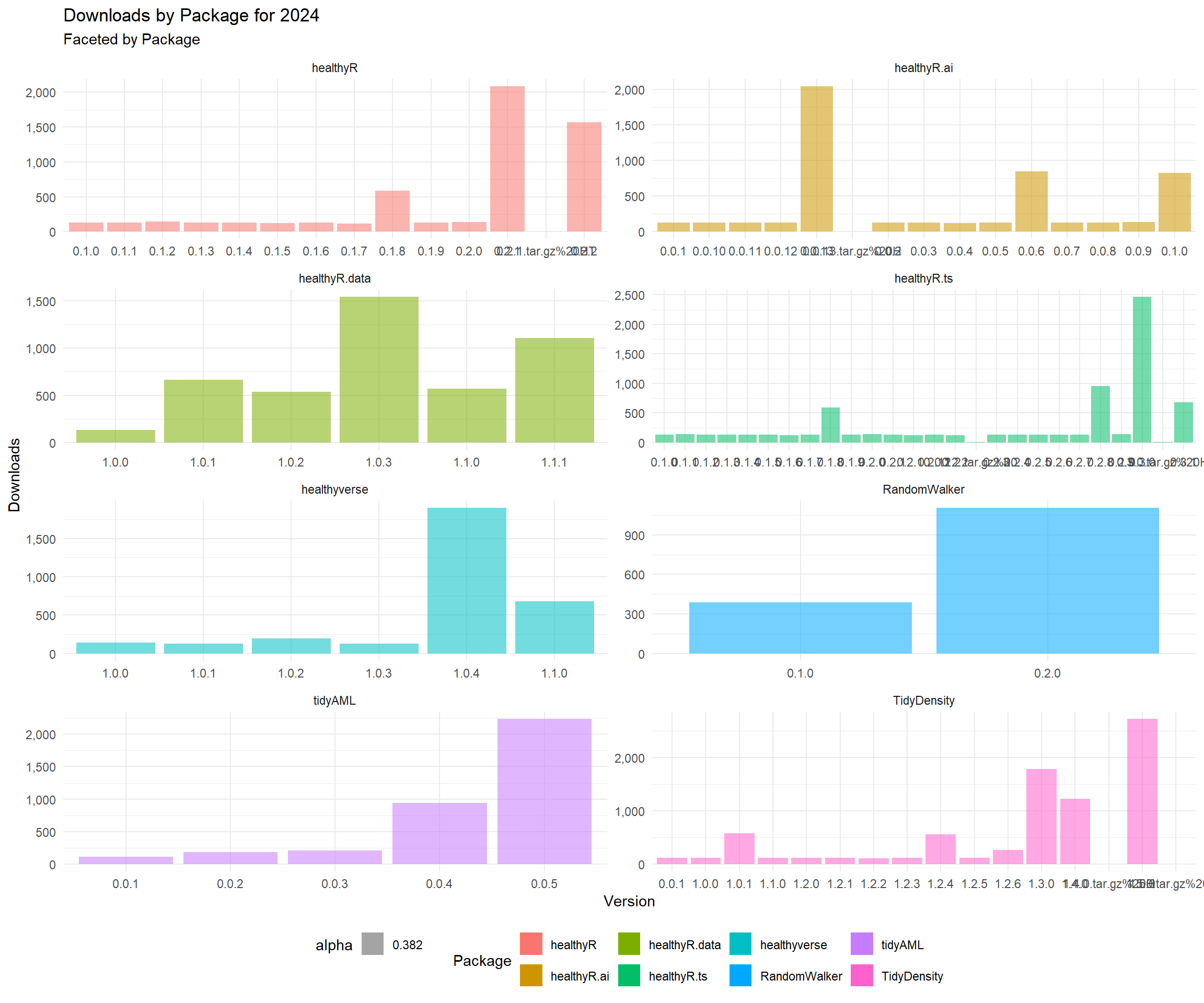
data_tbl %>%
count(package, version) %>%
ggplot(aes(x = version, y = n, alpha = 0.382)) +
geom_col(aes(group = package, fill = package)) +
facet_wrap(package ~., ncol = 2, scales = "free") +
scale_y_continuous(labels = scales::label_number(big.mark = ",")) +
theme_minimal() +
theme(legend.position = "bottom") +
labs(
title = "Downloads by Package for 2023",
subtitle = "Faceted by Package",
x = "Version",
y = "Downloads",
fill = "Package"
)
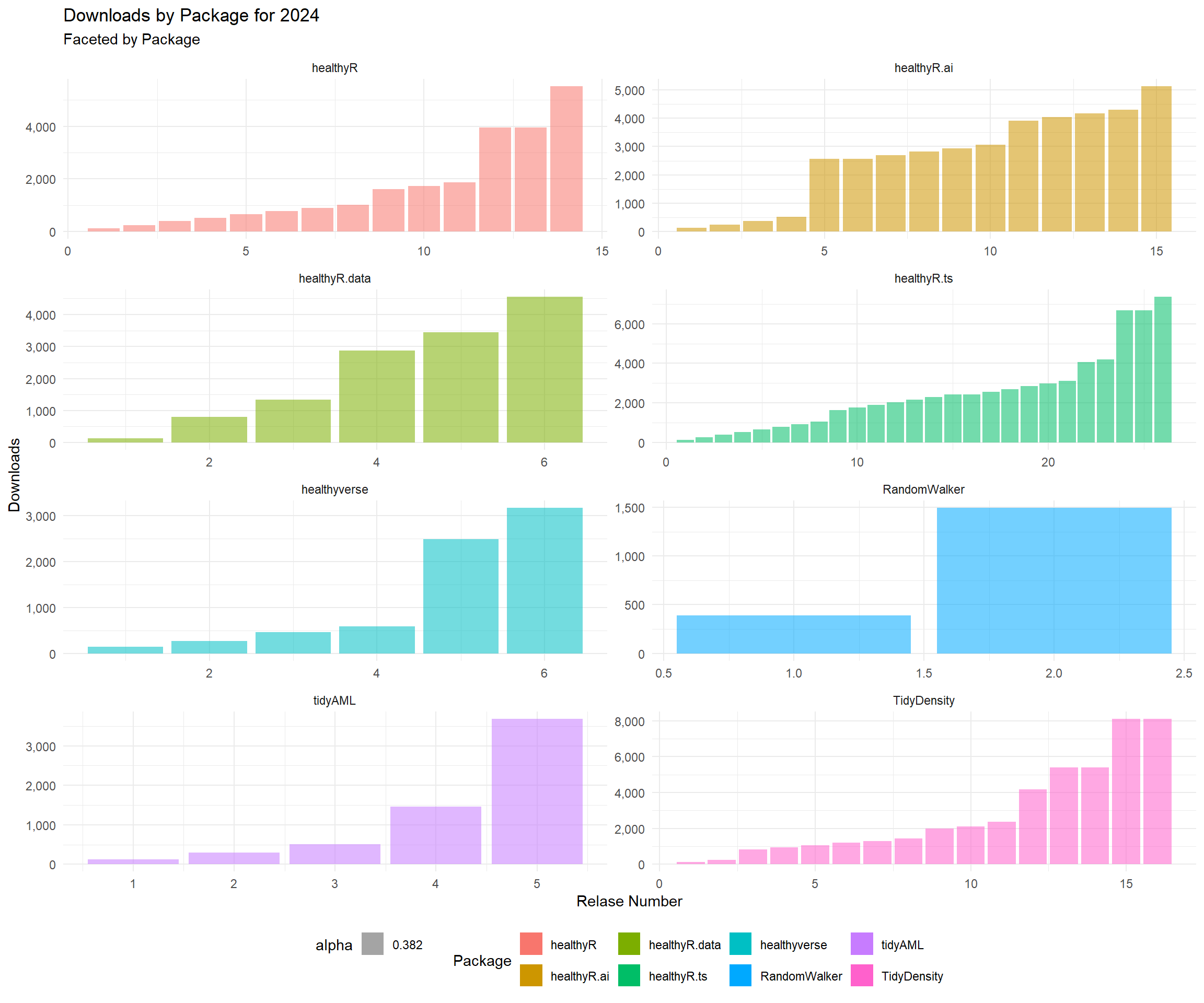
data_tbl %>%
count(package, version) %>%
group_by(package) %>%
mutate(cumulative_downloads = cumsum(n)) %>%
mutate(record = row_number()) %>%
ungroup() %>%
ggplot(aes(x = record, y = cumulative_downloads, alpha = 0.382)) +
geom_col(aes(group = package, fill = package)) +
facet_wrap(package ~., ncol = 2, scales = "free") +
scale_y_continuous(labels = scales::label_number(big.mark = ",")) +
theme_minimal() +
theme(legend.position = "bottom") +
labs(
title = "Downloads by Package for 2023",
subtitle = "Faceted by Package",
x = "Relase Number",
y = "Downloads",
fill = "Package"
)
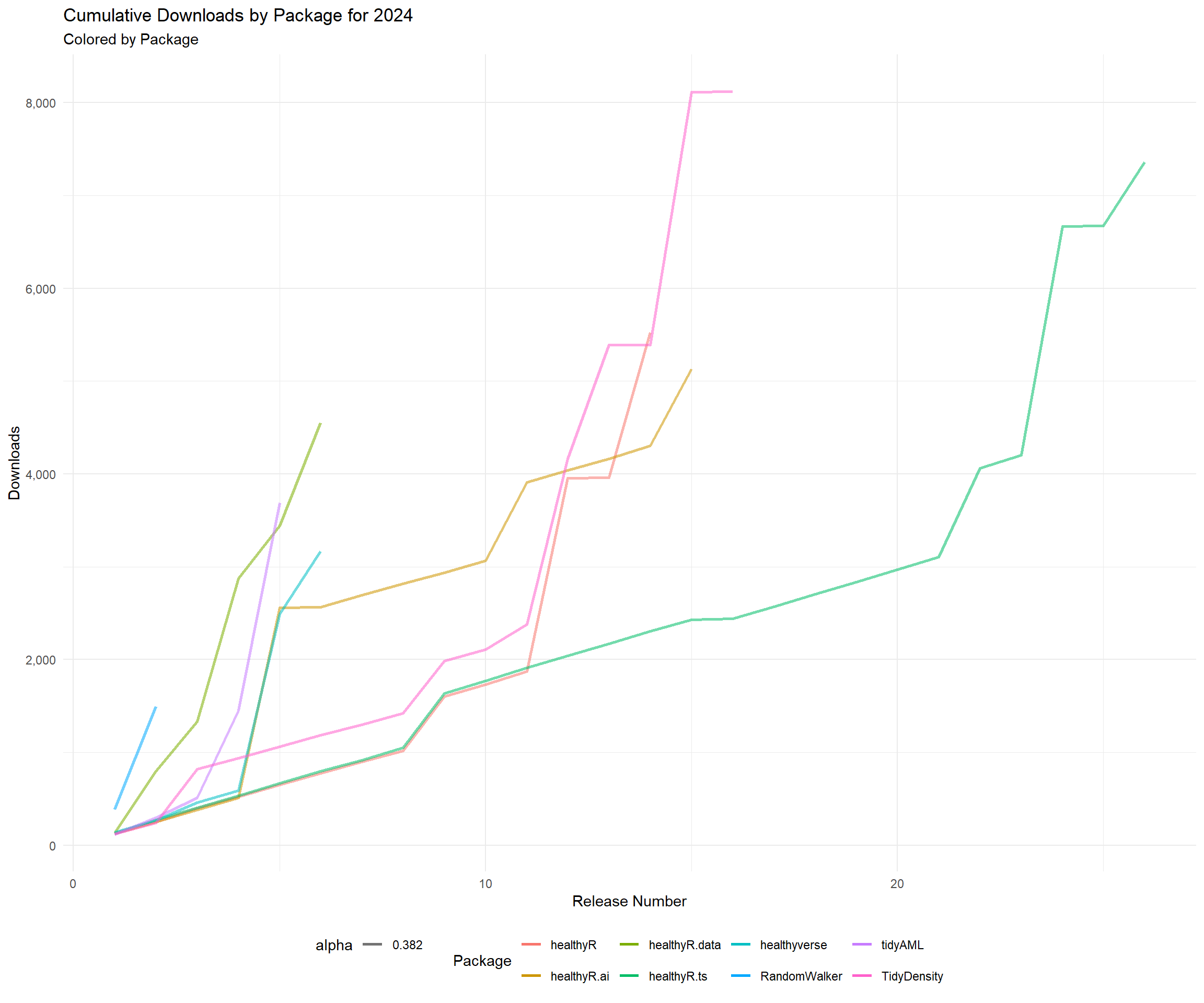
data_tbl %>%
count(package, version) %>%
group_by(package) %>%
mutate(cumulative_downloads = cumsum(n)) %>%
mutate(record = row_number()) %>%
ungroup() %>%
ggplot(aes(x = record, y = cumulative_downloads, alpha = 0.382)) +
geom_line(aes(color = package, group = package), size = 1) +
scale_y_continuous(labels = scales::label_number(big.mark = ",")) +
theme_minimal() +
theme(legend.position = "bottom") +
labs(
title = "Cumulative Downloads by Package for 2023",
subtitle = "Colored by Package",
x = "Release Number",
y = "Downloads",
color = "Package"
)
Time Series Graphs
Now lets get some time-series graphs.
library(healthyR.ts)
pkg_tbl <- readRDS("00_data/pkg_release_tbl.rds")
data_tbl %>%
summarise_by_time(.date_var = date, n = n()) %>%
ts_calendar_heatmap_plot(.date_col = date, .value_col = n, .interactive = FALSE)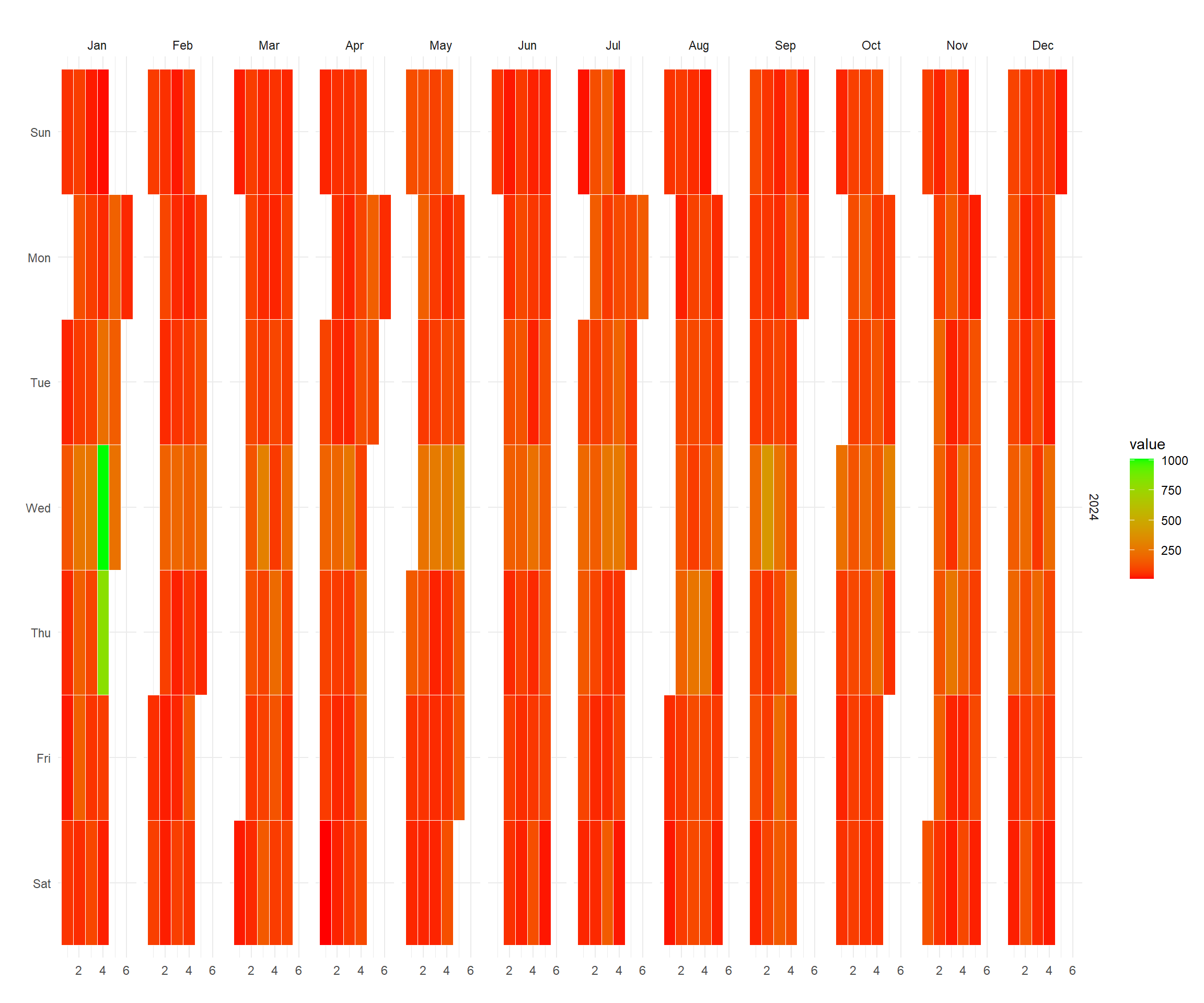
data_tbl %>%
ts_downloads_tbl(.by_time = "day", package) %>%
ggplot(aes(date, log1p(value))) +
geom_point(aes(group = package, color = package), size = 1) +
ggtitle(paste("Package Downloads: {healthyverse}")) +
geom_smooth(method = "loess", color = "black", se = FALSE) +
geom_vline(
data = pkg_tbl
, aes(xintercept = as.Date(date))
, color = "red"
, lwd = 1
, lty = "solid"
) +
facet_wrap(package ~., ncol = 2, scales = "free_x") +
theme_minimal() +
labs(
subtitle = "Vertical lines represent release dates",
x = "Date",
y = "log1p(Counts)",
color = "Package"
) +
theme(legend.position = "bottom")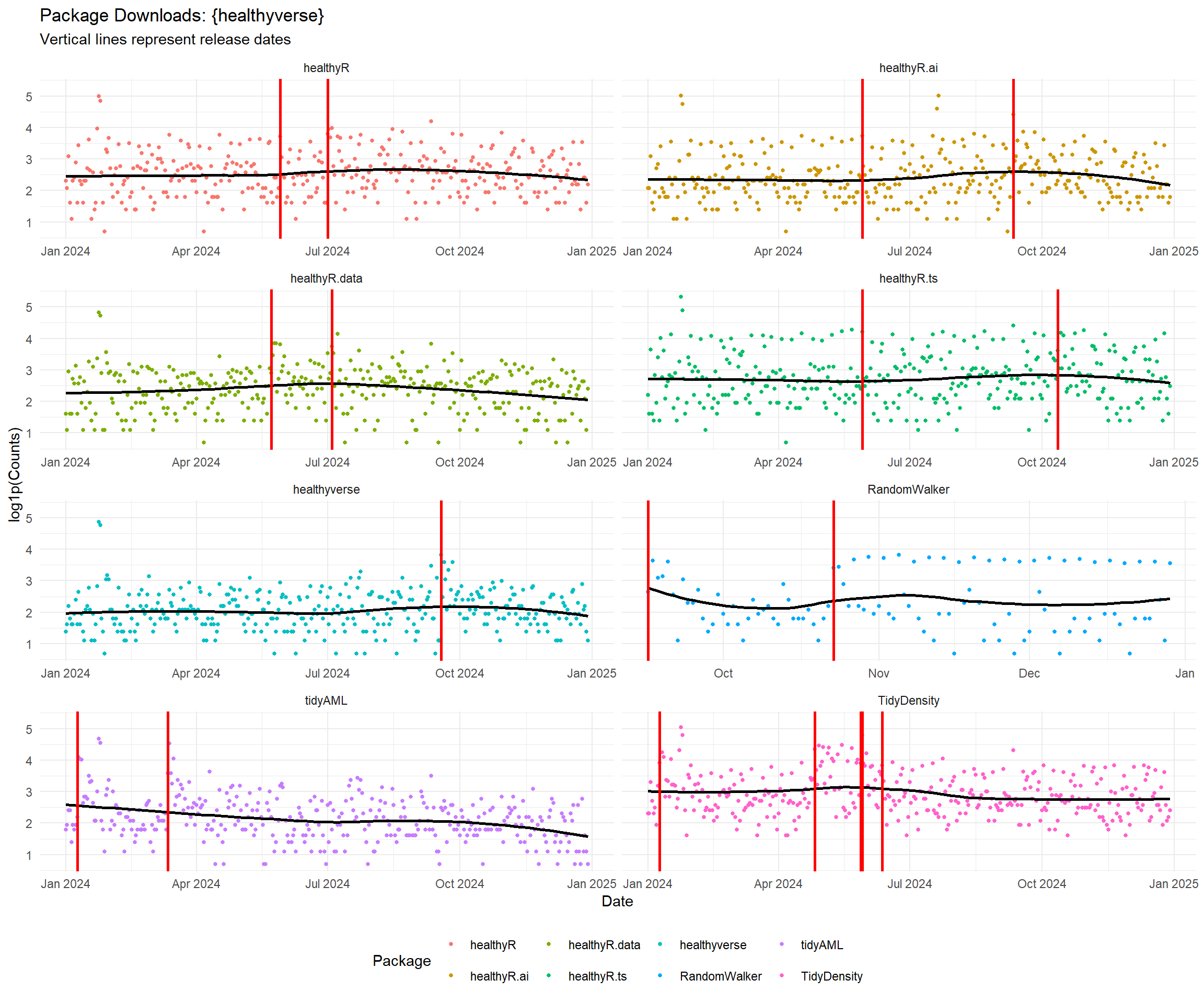
data_tbl %>%
ts_downloads_tbl(.by_time = "day") %>%
rename(Actual = value) %>%
tk_augment_differences(.value = Actual, .differences = 1) %>%
tk_augment_differences(.value = Actual, .differences = 2) %>%
rename(velocity = contains("_diff1")) %>%
rename(acceleration = contains("_diff2")) %>%
pivot_longer(-date) %>%
mutate(name = str_to_title(name)) %>%
mutate(name = as_factor(name)) %>%
ggplot(aes(x = date, y = log1p(value), group = name)) +
geom_point(alpha = .2) +
geom_vline(
data = pkg_tbl
, aes(xintercept = as.Date(date), color = package)
, lwd = 1
, lty = "solid"
) +
facet_wrap(name ~ ., ncol = 1, scale = "free") +
theme_minimal() +
labs(
title = "Total Downloads: Trend, Velocity, and Accelertion",
subtitle = "Vertical Lines Indicate a CRAN Release date for a package.",
x = "Date",
y = "",
color = ""
) +
theme(legend.position = "bottom")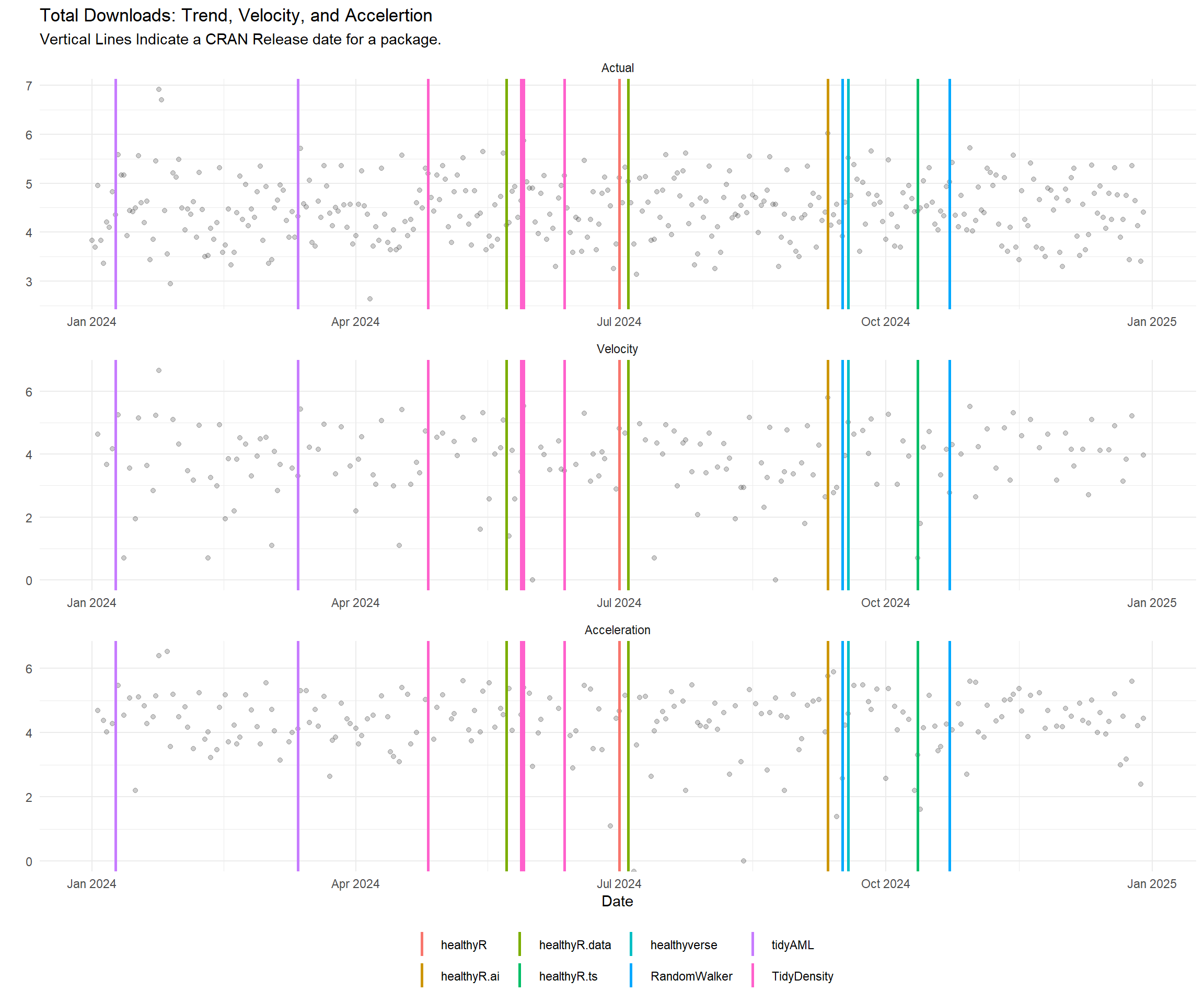
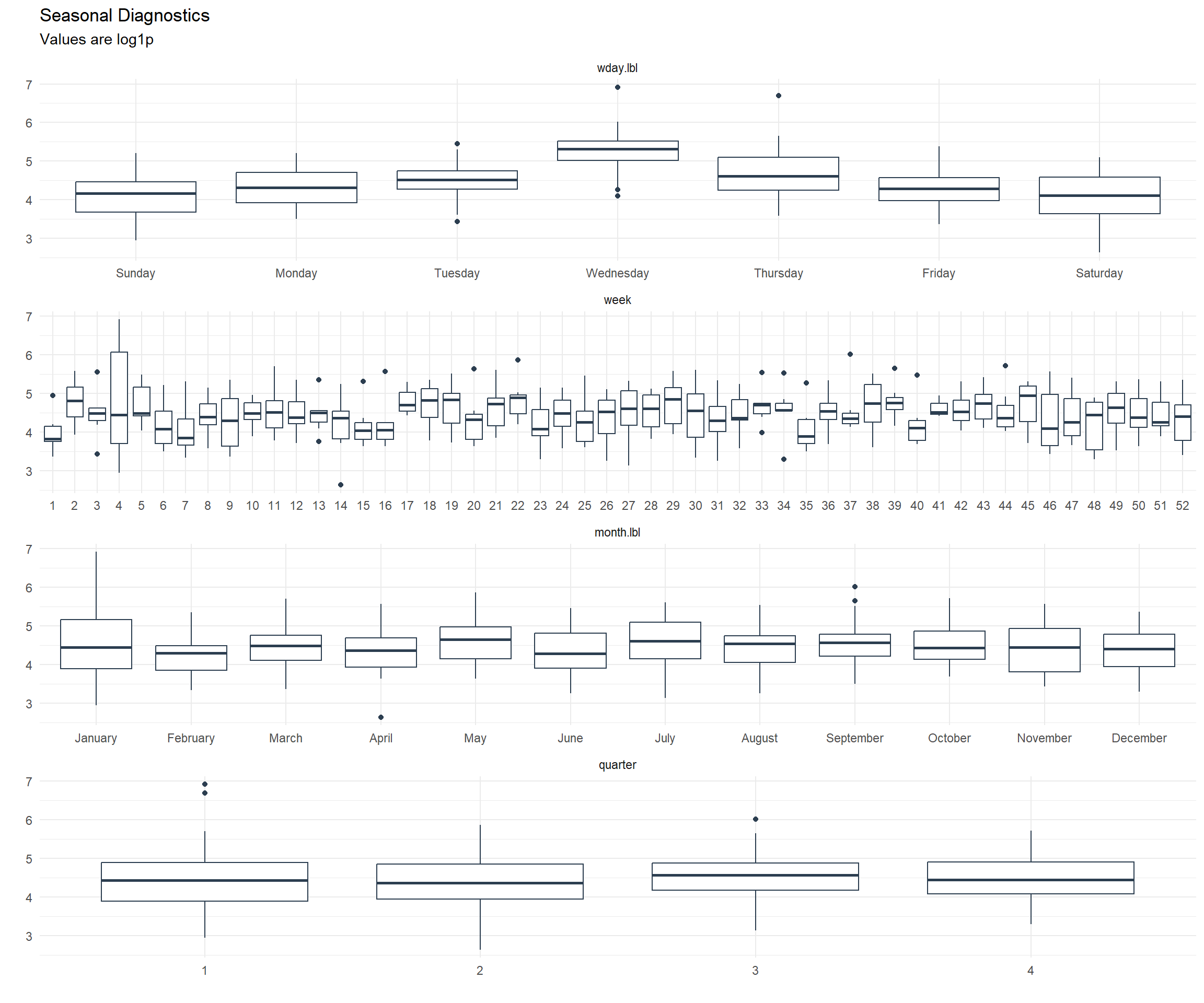
data_tbl %>%
ts_downloads_tbl(.by_time = "day") %>%
plot_seasonal_diagnostics(
.date_var = date,
.value = log1p(value),
.interactive = FALSE
) +
theme_minimal() +
labs(
title = "Seasonal Diagnostics",
subtitle = "Values are log1p"
)
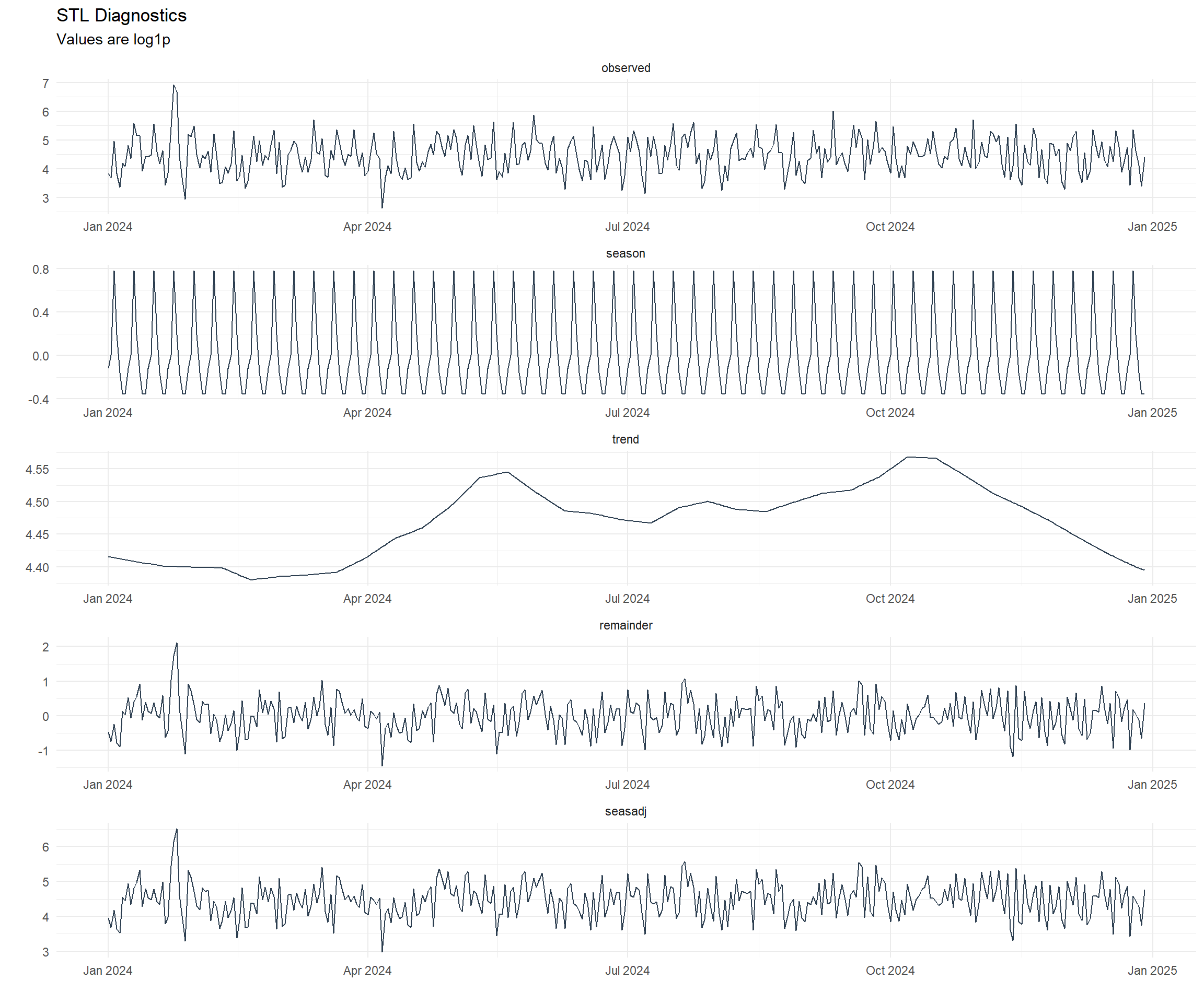
data_tbl %>%
ts_downloads_tbl(.by_time = "day") %>%
plot_stl_diagnostics(
.date_var = date,
.value = log1p(value),
.interactive = FALSE
) +
theme_minimal() +
labs(
title = "STL Diagnostics",
subtitle = "Values are log1p"
)
Mapping
So now that we have seen all the downloads in variaous ways, where did they all come from? Lets take a look.
library(tmaptools)
library(countrycode)
library(mapview)
library(htmlwidgets)
library(webshot)
# mapping_dataset(.data_year = "2023") %>%
# head() %>%
# knitr::kable()
l <- map_leaflet()
saveWidget(l, "downloads_map.html")
try(webshot("downloads_map.html", file = "map.png", cliprect = "viewport"))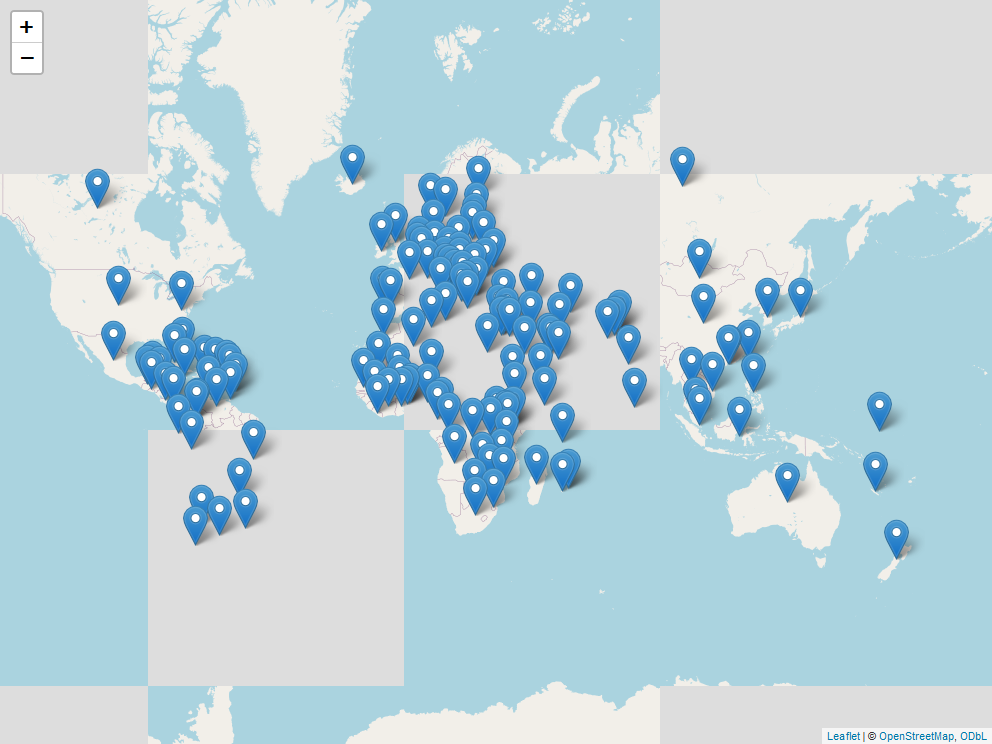
There was a total of 147 different countries that downloaded healthyverse packages in 2023.